In the Overview section, we looked at Hierarchy as a whole, talking about both the data-language and its persistence features. In this section, we'll focus mainly on the Hierarchy language to give you a good, high-level understanding of its syntax and how it works. Enjoy!
Hierarchical data is used throughout the applications we develop. Just to name a few key uses: JSON Objects, XML config files, database results such as those returned from Hibernate or JPA, web services... As Java developers, most of us use it on a daily basis. What if Java had a new data type to hold this kind of data? Might this save us all a lot of time and energy if creating hierarchical data was just as easy to do as creating a regular Java class?.
The Hierarchy meta-compiler extends the Java language with a new language for data. Specificaly, it adds a new hierarchical data-type (called a Matrix) along with new operators to work with it. A description we like to use that seems to sum up Hierarchy nicely is: think of it as a compiler that adds in a new, XML-like language directly into Java.
In fact, Hierarchy adds three, new file-types to Java, all of which map to equivalent file types in XML. Hierarchy adds:
- .matrix file - which is equivalent to the .xml, and holds hierarchical data
- .schema file - which is equivalent to an .xsd, and has the schema information for describing the structure of the data.
- .mjava file - which is equivalent to the .xsl file. This one isn't an exact match. A .xsl is an entire language for processing xml data, while the .mjava file is just a regular .java file with new instructions for accessing the hierarchical data in the .matrix files.
At this point, let's dive right in and take a look at an example. We hope you see, it's very intuitive. Let's say we're building a website for a pet store. Specifically, we'll build the news section for the site's homepage. Here's what the page looks like:
Willie's Pets and Things
news
Adopt-a-Pet Day is this Sunday!
March 17th
Your chance to adopt a lonely doggie is right around the corner. Come by Willie's Pets on Sunday to find the personality that's a perfect match for you!
20% off Fanciful Dog Spread
March 12th
For one day only, come and pick up your tub of Fanciful Dog Spread! A truly refined and tasteful topping your dog will find dreamy.
Now, as we mentioned, we're just going to focus on the news section of this page. First, let's create a file with all the hierarchical data. As we talked about earlier, this type of data is stored in a .matrix file (which is equivalent to the .xml). Our matrix file will contain all the news story data for this page:
package com.williespetstore;
import java.util.Date;
import java.text.DateFormat;
MATRIX WilliesPetstore.Content USES (News.Schema) {
NEWS: {"HomePage News Blurbs"} {
NEWS.STORY +`Adopt a Pet`: {
DateFormat.getDateInstance().parse("March 17, 2010"),
"Adopt a Pet",
"Your chance to adopt a lonely doggie is right " +
"around the corner. Come by Willie's Pets on Sunday "+
"to find the personality that's your perfect match!"
};
NEWS.STORY +`Fanciful Dog Food`: {
DateFormat.getDateInstance().parse("March 10, 2010"),
"20% off Fanciful Dog Spread",
"For one day only, come and pick up your tub of " +
"Fanciful Dog Spread! A truly refined and tasteful " +
"topping your dog will dream about."
};
}
}
The Willie's PetStore matrix file:
WilliesPetstore$__$Content.matrix
As you can probably see, the .matrix file has a very similar structure to XML. It has a root node called
WilliesPetstore.Content, which has a child,
NEWS node. And then, this
NEWS node itself is a parent to multiple, child,
NEWS.STORY nodes. Now, in the
NEWS.STORY nodes, this is where we're storing the actual values, which are held in different
fields. For instance, in the first
NEWS.STORY node, the strings, "Adopt a Pet" and "Your chance to adopt a lonely doggie..." are both values stored in fields. 'Fields' in Hierarchy are equivalent to 'attributes' in XML.
Conceptually, you should think of a Matrix as a new, data type for Java. It's on the same level as a regular class. In fact, matrices aren't static like XML documents, but, instead like instances of a Java class, are mutable. You can dynamically add, remove, and modify values at runtime. You can even add whole new subtrees. We created Hierarchy with the idea of building on what's already in Java, and matrices were designed to naturally fit in as a new, third data-type. In between primitive types (like int's) and classes, matrices are a third, new data-type available for you to use.
The next file type is the .schema file. Let's define the schema for the news story matrix. We'll create a new file named News$__$Schema.schema and add the following code:
package com.williespetstore;
SCHEMA News.Schema {
DESCRIPTOR +:%NEWS {
FIELD.NAMES: { +:%NewsSectionName };
FIELD.TYPES: { :String };
DESCRIPTOR +:%NEWS.STORY {
FIELD.NAMES: { +:%StoryDate, +:%Title,
+:%StoryContent };
FIELD.DESC: { "The date of the story",
"The title of the story",
"The content of the story" };
FIELD.TYPES: { +:"java.util.Date", :String, :String };
}
}
}
The News Story schema file:
News$__$Schema.schema
The one part that confuses developers the most in schemas is how to define the fields for a descriptor. You do this with the FIELD.NAMES, FIELD.TYPES and FIELD.DESC descriptors. But, before we talk about these FIELD descriptors, we need to look back, and take another look at the matrix example. In the WilliesPetstore.Content matrix, you may notice that for each of the field values, matrices have no field names!
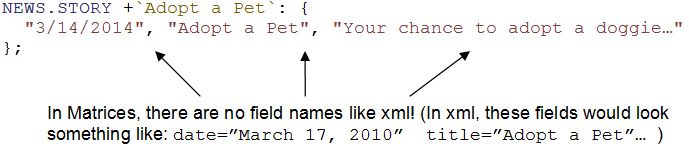
The reason there are no field names is because for a value, the field it belongs to is determined by its positon! So, for the NEWS.STORY descriptor, the first value in the fieldset is always going to be the date, the second is going to be the title, and the third is going to be the storyContent. And, the place where you set this relationship up is in the schema. Here, you can see this relationship below:
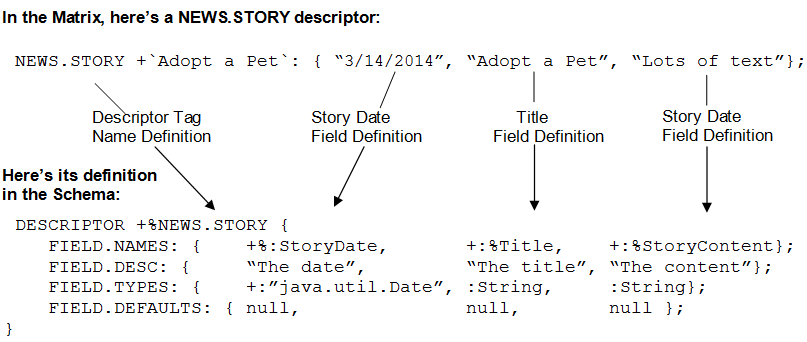
As you can see above, in a matrix, the position of the value determines which field it belongs to. And position is also used in the schema, in the field's definition. So, for the first field, StoryDate, all its field information is defined in the first position of the FIELD descriptors! And, for the second field, Title, all its field information is defined in second position, and so on...
Matrices do still allow you to do the "fieldName='fieldValue'" style of mapping, but we actually found that this extra text tends to make your code messy, so when we can, we use the syntax without the field names.
Compared to XML schemas, the structure of matrix schemas should be easier to follow. By just looking at the schema file and comparing it with the matrix file, you should easily see that the structure of the Desciptor definitions in the schema correspond to the structure of the descriptors in the matrix.
Jump back to the matrix example. In the matrix, we can see we have a parent, NEWS node, which holds multiple child, NEWS.STORY nodes. Now, how do we define this parent-child relationship in a schema? If we move forward again to the schema example, all you have to do to define this relationship is nest the NEWS.STORY nodes inside the NEWS nodes. It's tha simple! Check it for yourself by looking at the schema example. In the schema, you should notice that the NEWS.STORY definition is indeed nested inside the NEWS definition.
Creating schemas in Hierarchy takes much, much less time than creating schemas in XML. In Hierarchy, since schemas are required, we worked really hard on making them extremely easy to use. An XML schema can take an hour or two to create. A comparable Hierarchy schema will take 15 minutes. And because matrices and schemas are compilied, unlike xml, the meta-compiler prevents you from making mistakes. You'll never have search for the correct file path or scan your code for a misspelled tag again. We found working with matrices and schemas is hugely easier than working with XML and JAXB, saving us developers a great deal of time.
So now, as a last step, let's create a console application that accesses the matrix and prints out the matrix's content in an embedded java file. This console app outputs the home page to standard out (of course, for a web page, we'd normally use a JSP or JSF file, but for the sake of simplicity, we'll output the page to the console). To create this app, we'll use the last file type, the .mjava file:
package com.williespetstore;
import MATRIX com.williespetstore::WilliesPetstore.Content;
public class WilliesPetStoreConsoleApp {
public static void main(String[] args) {
System.out.println("Willie's Pets and Things");
System.out.println("");
System.out.println("news:");
for(DESCRIPTOR<WilliesPetstore.Content->NEWS->NEWS.STORY>
newsStoryDesc :
WilliesPetstore.Content->NEWS->NEWS.STORY{*}){
System.out.println(newsStoryDesc:>Title);
System.out.println("________________________________");
System.out.println(
(newsStoryDesc:>StoryDate).toString());
System.out.println(newsStoryDesc:>StoryContent+"\n");
}
ANNOTATIONS {
DEFAULT { return null; }
}
}
}
Embedded Java file for Willie's Pet-Store console-app:
WilliesPetStoreConsoleApp.mjava
These "embedded" Java files are basically the same as regular a Java file except they have some new instructions. Notice how this file really is just a regular Java class, except for some extra instructions we've added for accessing the matrices. These new, matrix instructions are all in bold. Embedded Java files end with a .mjava file extension.
And, just to finish this sample, let's try and run it. Here's the console output from this application:
Willie's Pets and Things
news:
Adopt a Pet
_____________________________________________________
Wed Mar 17 00:00:00 PDT 2010
Your chance to adopt a lonely doggie is right around the corner.
20% off Fanciful Dog Spread
_____________________________________________________
Wed Mar 10 00:00:00 PST 2010
For one day only, come and pick up your tub of Fanciful Dog Spread!
You may be wondering if you can use your existing Java code and the libraries you're used to with Hierarchy.
Code compiled by Hierarchy is 100% compatible with existing Java. The reason is because it's a translator that translates code written in this extend Java syntax into just pure Java (The way you can think of this process is similar to how the Perl compiler does translation, translating code written in Perl into C). Since the translated code is just pure Java, you'll be able to use all the exisiting Java libraries you're familiar with. And (not to confuse you), but we don't call Hierarchy a translator or a compiler, we call it a "metacompiler".
Oh, and the metacompiler is free! A developement tool like this really needs to in the hands of developers, so the core compiler will always be free.
... In the future, we'll also include a short tutorial on how to use Frictionless Persistence. Because this is just an (early) alpha version we are still working out the syntax on how to use it, but to give a brief overview of how this will work, it's very simple. First, have the internal persistence server running in the background. Then, for any persistent Matrix object all you need to do to to access the most up-to-date data is to access it normally (Hierarchy takes care of keeping you Matrix object updated with the most recent info):
// printing out user info from a persistent matrix system.out.println(MyPersistentMatrix->Myuser[`Patrick Levy`]:>address);
And, to make changes, we may support two techniques. If you're persistence needs are eventually consistent, you simple need to make regular assignments to the Matrix and Hierarchy takes care of the rest, persisting the value back to the internal server on its own.
MyPersistentMatrix->Myuser[`Patrick Levy`]:>age = 27; // changing Patrick's age in the persitent matrix
And, a more transactional syntax if you want all the updates to occur at the same time:
transaction {
MyPersistentMatrix->Myuser[`Patrick Levy`]:>age = 27;
MyPersistentMatrix->Myuser[`Patrick Levy`]:>fullname = "Patrick Dawson Levy";
MyPersistentMatrix->Myuser[`Patrick Levy`]:>address = "1333 Market St.";
} catch (Exception e) {
rollback();
}
But, this is all being finalized at the moment. We'll have an updates on Frictionless Persistence later.
Before we move on, we found it's useful to revisit questions of...
...So, What Exactly is Hierarchy? Is it XML? Is it JSON?
As we said in the overview, no to both! You can think of it as its own, proprietary version of XML/JSON. Hierarchy's main purpose is that since data is so important, it needs to be directly apart of our programming languages. Its goal is to be the one, all powerful data-structure that can handle almost all forms of data (SQL query-results, NoSQL documents, XML config-files, JSON objects...).
This why we've included the "easy-to-use but powerful" schema you just saw previously. This elegant schema allows maximum flexiblity in working with almost any data source and any data format. It allows you to describe the structure of them in unlimited ways as our schemas are easily extensible in the types of schema elements it can hold.
And, these schemas are fully understood by the compiler. So when you're making a matrix, the compiler finds any problems with its structure or syntax. For instance, it finds when you've forgotten to wrap your child elements in your parent element, spelling mistakes in your tag names, and improper assignments (type mismatches) when you supply a string instead of int. We've personally found it a joy to work with, catching tons of mistakes for you.
And, just like for matrices, because the meta-compiler understands your schemas, it can also check whether you're correctly using our matrix-access operators to query your matrices. And, just like when creating matrices, the compiler knows if you forgot to include a tag name in your access expression, or made a mis-spelling.
In addition, in the future, our schemas will allow the IDE to do on-the-fly checking of these matrices and matrix access expressions, and also when your define a matrix element, it'll offer usage suggestions in drop-down list.
In XML, schemas are a nuisance. In Hierarchy, they provide an ease and a flexibility to developers in how they work with data.
Still, Matrices sound a lot like JSON
Yes, both are similar in that Hierarchy's Matrices are a hierarchical data structure that's directly apart of the programming language (for JSON, they're included in JS and Python amongst other languages). But, unlike JSON, matrices are built from the ground up for working with data. Again, the Hierarchy-language's purpose is a lot Microsoft's LINQ technology, to build support for data right into the language so that working with it is significanlty easier. And also similar to LINQ, the results are lots of improvements of various importance so that you'll have to typically write much less code and have much less complexity. For instance, there are small things like labels on data elements that make accessing elements simple, and large things like the our matrix-access language that is similar to XPath much better than XPath with complex queries. And, since the matrix-access language fully apart of Java, devs can use their own variables in their query filters.
Are there other ways in which Hierarchy is better for programming with data than JSON?
Because Hierarchy has initutive schemas, you can also create methods around the parts of your matrices, designing entire libraries around them. You do this in your method parameters using what we call 'descriptor variables.' With descriptor vars, you can pass in different subtrees of your matrix. You can see one in the WilliesPetStoreConsoleApp.mjava file above, it's defined in the for loop:
DESCRIPTOR<WilliesPetstore.Content->NEWS->NEWS.STORY>
What's great is that is that you can define the specific part of the Matrix you want to access (it's the '<WilliesPetstore.Content->NEWS->NEWS.STORY>' part of the descriptor variable). This let's you make sure you know where your variable is pointing. This is important in complex Matrices as it's veryeasy to get confused. We've found them extremely useful in our day-to-day programming.
Is there anything else you haven't mentioned?
Yes, note that our Matrix objects do not need to be persistent. In fact, we find half the time, we use them
non-persistently: In most business applications, there seems to be a lot of static content and settings that is well suited for standard Matrix objects. And what's nice is that Matrix objects are allowing you to treat persistent and non-persistent data the same!
This let's you start by creating a regular Matrix-object for you data (for instance, maybe you need an events calendar that isn't updated too often). But in the future, you can instantly change it to a persistent object to if you need to (maybe you find you're changing the calendar more than you thought, and need to add in an admin section to make changes on the fly). Think of how this is done now. In Java, we might decide to start holding your calendar content in XML files (or, in other languages, in JSON). And, then when we need to migrate it to a database, we'd have to undergo the painful process of transforming this data into a NoSQL or SQL DB. Then, we need to rewrite all the code that accessed this information.
In Hierarchy, all data is treated the same. Matrices are a form of data abstraction that lets you move seamlessly from non-persistent to persisent data, or even move it to a web-service without changing your application code.
Why didn't you use Google Protocol-Buffers for your matrices?
This is a harder call, and we may allow developers to use the Protocol-Buffer language as well in the future, but even Protocol Buffers aren't custom designed for
programming directly with data. Hierarchy's matrices and schemas are (in our biased opinion) better to do actual programming with.
Why did you use upper-case in your keywords like MATRIX and SCHEMA?
We did this in case Java every used one of the keywords in future versions. This way, your code would never lose compatability. But, since so many people have mentioned it, we may changes this to lowercase in the release version.
How does Frictional Persistence fit in? And, when would I use it?
Also as mentioned in the Overview section, Frictionless Persistence is an additional feature to the Hierarchy data-language that is just as important as the language itself. It is the idea that hierarchical data-objects would themselves make great databases, and that this feature should be directly supported by the programming language itself.
And, when would you use it? Once Frictionless Persistence is done, Hierarchy will replace most of the situations you'd use a SQL database (and then some...). So, for instance, if you need to create a user-login system for your web site or the inventory system for your company's warehouse application, you'd use Hierarchy's matrices. And, it'll perform super fast, as fast as an in-memory database. You'll also find since persistence is so easy to create, you'll use it in situations where you normally wouldn't. For instance in our test applications, we use matrices for any part of an application that contains any form of content. It's great for the dynamic generation of text, menus and layout for websites.
When would you not use it?
Like most in-memory databases, Hierarchy is not as good with Big Data as you need to be able to load the entire database into RAM. But lately, even Big Data is possible as RAM is getting cheaper and cheaper - you can buy a server with 256 GB for $5k these days.
So, in the future, will it scale?
Eventhough we said Big Data is
currently not a focus for us, "Scalability with ease-of-use" and performance are hugely important principles for our software. Our goal is make Frictionless Persistence so you can initially use it with no concern for performance needs (just use the Peristent Matrices almost like you would any other object). And as your needs grow, you'll be able to control you system's data-performance with increasing degrees of granularity.
The main way this will work is the matrices are a performance abstraction for your data! So, behind the scenes, you'll be able to customize them more and more by adding in server nodes, and (just as importantly) adding in custom code to be able to load-balance, cache or query you data to meet your changing performance needs. But, Frictionless Persistence is just an early alpha version so this is still being worked out.
...And, in the future, we have a solution for huge sets of data that is in the works (ask us and we can talk to you about it)...
Hierarchy seems like it's trying to do to much and is too ambitious to be successful
As we have been mentioning, Project Hierarchy is admittedly ambitious. But, someone needs to try to do things right (not just good enough), to find out if there is a better way for us devs to work. Even if Project Hierarchy fails, we hope its ideas will seep into the Java community and the rest of development world. You may say this should be the job of software research, but we find that research is often too impractical, too academic. But, on the other hand, products (even open source) are too conservative in their approach. As we said in the intro, ProjectHierarchy is a true open-source project in that it as half science-project, half-product. Even if it fails as a product, it may succeed in validating some approaches to programming and data that may make their way into other languages. Sometimes if you fail, you still succeed.
That's it for this quick tutorial! Hope you found it easy to learn the fundamentals of Hierarchy - we worked really hard to balance simplicity with a rich set of features...
Next, click the arrow below to read about the benefits of using Hierarchy.


