Briefly, What is Hierarchy?
Hierarchy is admittedly ambitious - We, as developers, need to push things every once in awhile to see what is and what isn't possible. But this makes it tough to understand what exactly Hierarchy does. So, we created this overview section to explain things, giving a bird's-eye overview of Hierarchy and its persistence features. But it assumes you've already seen the our short video that introduces you to Hierarchy and is found on the previous page of this site (on the "Intro" page). If you haven't seen it yet, please go there now and come back here once your ready...
Hierarchy is what's called a NoDB database. A NoDB database is one where the technical aspects of how you work with persistent data are handled for you (which is why it's called a NoDB. This is typically implemented by having your own application objects as your databases (for a short overview on NoDB, click here). And, in Hierarchy, we've implemented NoDB in a very simple way, through a new data-object called a Matrix. A Matrix is a hierarchical data-structure just like JSON or XML. In fact, you can think of it as an easy-to-use, XML-like object that's native to the Java language itself. Matrices have their own, new grammar-rules added right in. So you can simply define one in your Java code:
package com.unconventionalthinking.mypackage;
// Definition of matrix in Hierarchy's extended Java syntax
MATRIX MyPhoneListMatrix {
`John`: { "313-555-1111"},
`Mary`: { "415-000-0000"},
`Bill`: { "248-444-9999"}
}
As you can see, this Matrix file even has Java's 'package' definition and is treated just like all your other Java files (in fact, you'll put it alongside all your other source-code). Moreover, a Matrix is just a normal Java-object but one that's been customized for data. It allows you to turn on persistence by simply adding one setting:
package com.unconventionalthinking.mypackage;
// Definition of matrix in Hierarchy's extended Java syntax
MATRIX MyPhoneListMatrix {
PERSIST: { :On };
`John`: { "313-555-1111"},
`Mary`: { "415-000-0000"},
`Bill`: { "248-444-9999"}
}
And when you access and modify this persistence object, you work with it just like it's a regular object and Hierarchy takes care of the rest. To access a matrix in your Java code, you'll use our matrix-access language, which is a lot like XPath but easier to use:
void printMary() {
System.out.println(MyPhoneListMatrix->`Mary`:>PhoneNumber);
}
And when you want to modify a value in this persistent matrix, you just do a regular assignment and Hierarchy takes care of persisting this value back to disk:
// Hierarchy will persist this back to disk for you
MyPhoneListMatrix->`Mary`:>PhoneNumber = "415-333-2222";
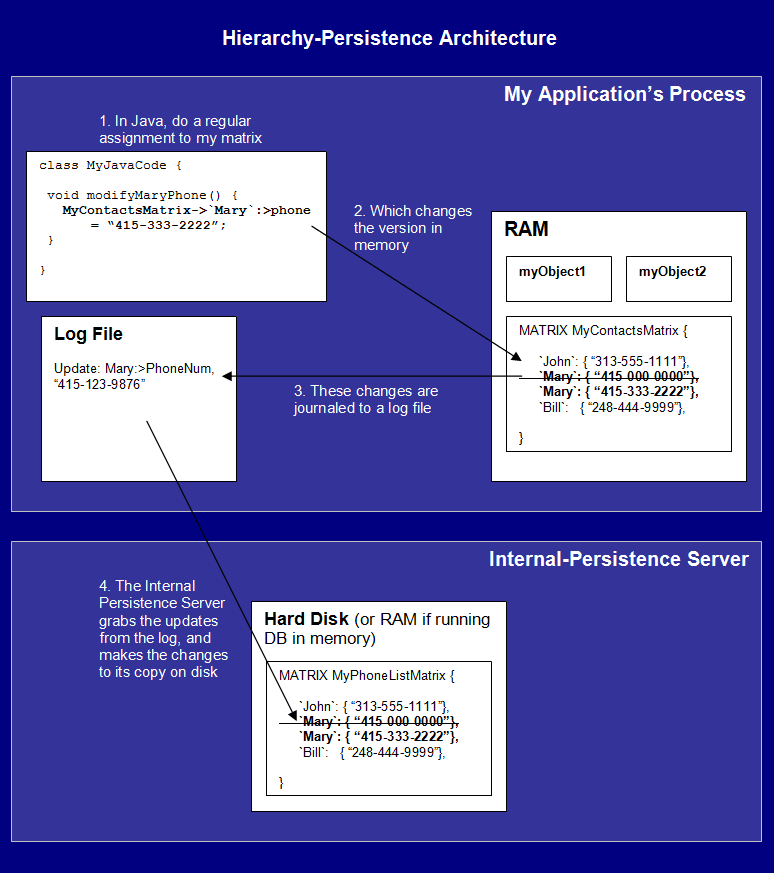
Hierarchy will collect these changes in a log file which will then be automatically pushed to our internal persistence-server. To see this, let's look behind the scenes at our persistent objects. First off, they are really no different than any other in your system and just like the rest, when your application starts up they live in RAM:
And note that like most in-memory DB's, Hierarchy holds the
entire database's contents in RAM. This means that your persistent matrices have all its values in RAM, no matter how larger they are.
So when you do a modification to a value in your matrix, in the background, there is an internal persistence-server running (either on the same system or on a separate server). This server picks up any changes your application makes to your Matrix. This is done using a log file, where your application will quickly log each change to disk. This way, your system can continue to run without the need to wait for the write operation to be sent and processed by the server. Then, after the write is logged, the internal persistence-server picks up this modification from the log file and automatically updates its own copy that's on disk:
The process is seamless and you really will treat your persistent objects like regular objects. But it does take a switch in thinking. Because even though there is an internal persistence-server running in the background, you have to think of the
matrix as your database,
not the copy of the data on the server! The main purpose of internal persistence-server is to simply copy changes made to your matrix back to disk. And unlike typical databases, your application will query and modify your database data directly (which is the values held in your matrices). In Hierarchy, your matrix objects are the database.
...At this point, before we continue, one important remark we need to make is that our database features are the newest addition to Hierarchy, many aspects of persistence are still in development!
...So to go on, we made some pretty big claims in our intro page when we said, "Hierarchy is both the easiest and one of the fastest database-solutions in the world." We know this sounds like sales-speak, but we hope this makes sense now that you understand how Hierarchy works behind the scenes. Hierarchy is not simply some convenient syntax-sugar for working with persistence, its purpose is to truly let you work with persistent data just like regular Java objects. And, this is especially true in the most painful aspect of working with database data, performance. Think of when we program against a database, how we naturally have to optimize our code to minimize access to the DB. Often, we'll need to stream a query result using cursors so we don't have to wait for a large dataset to be sent, or we'll cluster a group of insert operations together to decrease the number of trips across the network. This time-consuming work is (if not "the" most) one of the most important factors in designing our data-access code.
Like many NoDB solutions, Hierarchy solves these performance issues by being an "in-memory" database. And as you may have realized, this means that both reading and writing of Hierarchy's persistent data-objects occurs nearly at the same speed as accessing a normal Java-object. You never have to worry about whether a database access will bog down your system. In Hierarchy, your reads and writes occur in handfuls of CPU cycles, not milliseconds.
So if NoDB is the last way-point in the development of the database, Hierarchy is its pinnacle, taking things even past other NoDB solutions (with no disrepect to all the other great NoDB solutions out there, we're all heading to the same goal!). It does this by simplifying database programming to the point were it is nearly transparent, the database being fully integrated in the programming language itself. This persistence solution (called Frictionless Persistence) is only an alpha version, but we're really excited about the direction it's going.
So, What Exactly is Hierarchy?
Hierarchy has two main pieces:
- An "XML or JSON"-like data-language directly included into the Java language. It is custom built from the ground up for allowing you to program directly with your data: At it's core, Hierarchy's purpose is the same as LINQ, the Microsoft (love or hate them) technology for query. Like how LINQ made "query" a super easy and flexible part of C#, Hierarchy tries to take "data" to the next level by making it apart of the programming language itself.
- And, just as importantly, Hierarchy is a NoDB database that seamlessly allows our Matrix objects to be databases. Taken with the Hierarchy data-language, this may make Hierarchy the easiest persistence solution possibly ever.
Is it XML? Is it JSON?
No to both! You can think of it as its own, proprietary version of XML/JSON (closer to XML, but much better we'd like to think). And being proprietary may sound bad, but its purpose is not the same as XML or JSON.
Their main purpose is to be a standard format to exchange data. Hierarchy's is the belief that since data is so important, it needs to be directly apart of our programming languages. It adds in a
native data-structure and access language to Java
specialized for programming with data.
The benefits of having a solution built from the ground up just for programming with data is that, now, the compiler can understand the structure of your data - This is done through an easy-to-create schema that you use to define your Matrices (these are not at all like XML's verbose schemas!). Using these schemas, the compiler can now "see your data" and knows when you've made a mistake. It can catch when you have a problem in the structure your nodes, or are using the wrong data-type for a value (should have been an int, not a String), or simply made a small spelling mistake in a tag name. In practice, we've found it sometimes feels a bit like magic in the errors it catches. It has saved us a number of times from hours of needless debugging.
How does Frictional Persistence fit in?
Frictionless Persistence is an additional feature to the Hierarchy data-language that is just as important as the language itself. It is the idea that hierarchical data-objects would themselves make great databases, and that this feature should be directly supported by the programming language itself. You'll use it to replace any situation you'd use a SQL database (and most NoSQL databases). Frictionless persistence is how we should all work with persistent data now and in future.
Again, as we mentioned, persistence is our newest addition and only portions of it have been implemented so far (modifications to persistent fields work, but currently requires a lot of manual code; and dynamically updating fields is under development). It's an early alpha but does show a lot of promise.
What is the status of Hierarchy?
Our
Java meta-compiler (and its new language-features like the Matrix object) is a very stable beta, and quite useable. In fact, this entire site was built with Hierarchy, holding all the content, menus, and settings in matrices. But, we recommend sticking with Java 7 as we have not added in Java 8's new grammar features yet (in the works!).
And as for Frictionless Persistence (the ability to turn Matrix objects into databases), it is only an alpha, and not bullet proof at all. It works, but is very unstable (we are in the process of making much more reliable). It should only used for demo purposes and should not be used in production at this time!
Next, click the arrow below to go through a short tutorial on the Hierarchy language.